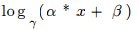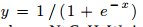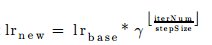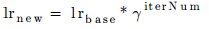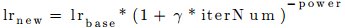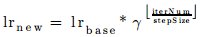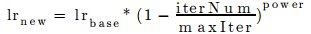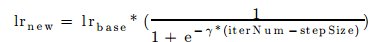This post is a brief compilation of the details related to the work done as a part of GSoC 2016, for the opensource library OpenDetection. It is a library with a specific focus on the subject of object localization, recognition, and detection in static as well as dynamic sequence of images.
For GSoC, 2016, I was selected to append Convolutional Neural Network related object classification and recognition modules into the library. The Proposal to the library can be accessed at: GSoC Proposal Link.
The following is a brief summary of the work done in the span of three and half months starting from May, 2016, till Mid-August, 2016.
The modules added to the library are:
- Building the library on CPU as well as GPU Platforms.
- Integration of caffe library.
- Addition of image classification module through c++ version of caffe.
- Addition of CNN training module through c++ version of caffe.
- A customized GTKMM based GUI for creating solver file for training.
- A customized GTKMM based GUI for creating a network file for training/testing.
- A customized GTKMM based GUI for annotating/cropping an image file.
- A Segnet library based image classifier using a python wrapper.
- An Active Appereance model prediction for face images using caffe library.
- Selective Search based object localization algorithm module.
Description:
Work1: The primary task undertaken was to make sure that the library compiled on both GPU and non-GPU based platforms. Earlier, the library was restricted to only GPU based platforms, due to the fact that, irrespective of the fact whether cuda library is installed in the system, the library fetched for headers from cuda. With a set of 45 additions and 1 deletions over 7 files, this task was undertaken.
Work2: The next target was to include caffe library components into the opendetection library. Opendetection library is like a pool of object detection elements, and without the integration of Convolutional Neural Networks, it would remain incomplete. there exist a lot of opensource library which support training and classification using CNN, like caffe, keras, torch, theone, etc, of which after we selected caffe, because of its simplicity in usage and availability of blogs, tutorials and high end documentation on the same.
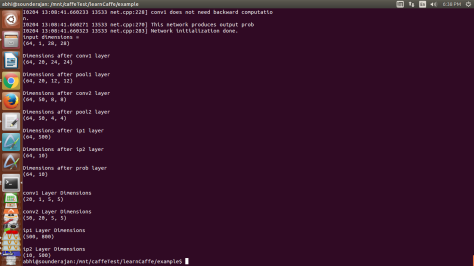
Work3: Once the library was included, the next was to include CNN based image classifier, over a c++ based code. Usually, researchers use the python wrapper provided by the caffe library to train a network or to use trained wieghts and network in classifying an image, i.e., assigning a predicted label to the test image. Herein, the task was completed with around 400 lines of code over 7 files. Any python wrapper reduces the speed of execution and in turn provides a lag in real time based applications. Also, the transfer of memory from cpu to gpu, on gpu based systems, is quite slow when the upper level code is in python. For this reason, we have directly accessed the c++ code files from the library and linked to our opendetection ODDetector class. As an example we have provided the standard Mnist digit classifier. In the example the user just needs to point a network file, trained weights and a test image, and the classification result will be obtained.
Work4: Just adding the classification abilities would make the library only half complete. Hence, for this reason we added the module which would enable the users to train their own module. With a total of around 250 changes made to 5 files, this training class was added to ODTrainer. User would only need to point towards the network and the solver file. Here again, a training example is added using Mnist digit dataset.
Work5: As stated above, a cnn based training requires a network file and a solver file. Any solver in caffe library has around 20 parameters. It is a tedious job to write the solver file from scratch, everytime a training has to be commenced. For this reason, to facilitate user feasibility over the solver properties a GUI has been introduced. This GUI has all the parameters involved in solver file. Also the user while using the gui has the facility to include or exclude a parameter. This particular commit had changes added or additions made to 9 files. The most crucial one was to add gtkmm library files to the source. GTKMM, link to understand gtkmm, is a library for involvement of gui based applications. We decided to move with GUI inclusion because, to make user handle solver file in an effective way, a set of 19 parameters had to be handled. If it were upto the c++ arguments to facilitate these 19 parameters, the outcome would have been a very cumbersome application. Also, not all parameters were to be added to the solver always, so a GUI appeared to be the most feasible option from the user’s end. A set of around 1250 lines of code made this module integrated into the opendetection library. The following are a few features of the GUI:
- The above code promts the user if any mistake is made from user-end.
- Pressing update button every time may be time consuming, hence the latest commits involve the fact that without pressing the buttons the parameters cab ne edited
- The main function of the update buttons after every parameter is make sure that, for future developments, if the intermediate parameters are to be accessed, the current version enables it.
- Not many open source libraries had this functionality
Work6: After solver, the next important thing to training is network file. A network file in CNN has the structure of the CNN, the layers, their individual properties, weight initializers, etc. Like the solver maker, we have created a module which provides a GUI to make this network. Every network has lot many properties, writing them manually into the file is a time consuming process. For this reason, the GUI was implemented, so that with just a few clicks and details any layer could be added to the network. a) The activation category includes the following activation layers
- Absolute Value (AbsVal) Layer
- Exponential (Exp) Layer
- Log Layer
- Power Layer
- Parameterized rectified linear unit (PReLU) Layer
- Rectified linear unit (ReLU) Layer
- Sigmoid Layer
- Hyperbolic tangent (TanH) Layer
b) The critical category includes the most crucial layers
- Accuracy Layer
- Convolution Layer
- Deconvolution layer
- Dropout Layer
- InnerProduct (Fully Connected) Layer
- Pooling Layer
- Softmax classification Layer
c) The weight initializers include the following options
- Constant
- Uniform
- Gaussian
- Positive Unit Ball
- Xavier
- MSRA
- Bilinear
d) Normalization layer includes the following options
- Batch Normalization (BatchNorm) Layer
- Local Response Normalization (LRN) Layer
- Multivariate Response Normalization (MVN) Layer
e) Loss Layer includes the followin optons: -Hinge Loss Layer
- Contrastive Loss Layer
- Eucledean Loss Layer
- Multinomial Logistig Loss Layer
- Sigmoid Cross Entropy Loss Layer
f) Data and Extra Layers:
- Maximum Argument (ArgMAx) Layer
- Binomial Normal Log Likelihood (BNLL) Layer
- Element wise operation (Eltwise) Layer
- Image Data Layer
- LMDB/LEVELDB Data Layer
g) Every Layer has all the parameters listed in the GUI, of which the non compulsory parameters can be kept commented using the radiobutton in the GUI,
h) One more important feature included is that user can display the layers. The facility to delete any particular layer, or add any layer in the end or in between two already implemented layers is also feasible through the usage of the GUI.
These properties of the GUI were made possible with a set of aorund 6500 lines of code over a range of arounf 12-15 files.
Work7: Active Appereance Model feature points over the face have had many application like emotion detection, face recognition etc. It’s of the personal researches we have undertaken which is based on finding these feature points using Convolutional Neural Networks. The network and the trained weights presented in the example in the library is one of the base models we have used. The main reason to add this feature was to show as to how widespread the uses of the integration of caffe library with opendetection could be to the users. Very few works exist on this end, and hence the purpose behind taking up the research. This is a very crude and preliminary model of the research, just for the young users to be encouraged as to the extent to which cnn may work and how opendetection algorithm would help facilitate the same.
Work8: Object reconition has two components: object localization and then classification. Classification module has already be included in the system, the localization part is introduced in this work. The task of object localization has been completed using selective search algorithm. The algo, when put simply, involves, Graph based image segmentation, followed by finding different features of the all the segmented parts, then finding closeness between the features of the neighboring parts and finally merging the closest parts and continuing futher till the algorithm is breaked. The image segmentation was adopted from Graph based image segementation mentioned here with proper permissions. The next part involved image preprocessing, which had conversion of BGR image to YCrCb, equalizing the first channel and reconversion of equalized YCrCb image to BGR color type. This was followed by the steps: image is stored in “.ppm” format as the segmentation code only prefers image in that format. Image is then segmented using the segment_image function and to find the number of segments, num, it is converted to grayscale and the number of colors there then represent the number of segments. The next step is to create a list of those segments. It is not often possible to create an uchar grayscale image mask with opencv here, because, opencv supports color version from 0 to 255 and in most cases the segments are greater than 255. Thus, we first store, every pixel’s value in the previous rgb image with the pixel’s location into a text file named “segmented.txt”.Finally, the steps were adopted, calculating histogram of the different features ( hessian matrix, orientation matrix, color matrix, differential excitation matrix), finding neighbors for each of the clustered region, finding similarities( or closure distance) between two regions based on the histogram of different features, merging the closest regions removing very small and very big clusters, and adding ROIs to images based on merged regions. This selective search has a set of 13 parameters which drive the entire algo here. The work here was completed with addition of around 2000 lines of code.
Work9: Segnet is a caffe derived library used for object recognition and segmentation purposes. It is a widely used library and the components are very much similar to caffe library. Thus there existed this logical compulsion to include the library so that the users may use segnet based training/classification/segmentation examples through opendetection wrapper. Addition of this library would allow segnet library users to attach it to opendetection in way as done with caffe library. Herein, the example included for now, is a python wrapper based image segmentation preview. The network and the weights are adopted from segnet example module.
Work10: Any image classifier training requires the dataset to be annotated. For this reason, we have added an annotation tool, which will enable users to label, crop or create bounding boxes over an object in image. The output of this tool is customized in a way which is required by the caffe library.
The features and some usage points involved are:
- User may load a single image from a location using the “Select the image location” button or the user may point towards a complete image dataset folder.
- Even if the user points to a dataset folder, there exists an option of choosing an image from some another location while the annotation process is still on.
- Even if user selects a single image, the user may load more single images without changing the type of annotation.
- The first type of annotation facility is, annotating one bounding box per image.
- The second, annotating and cropping one bounding box per image.
- The third one, annotating multiple bounding boxes per image, with attached labels.
- The fourth one, cropping multiple sections from same image, with attached labels.
- The fifth one, annotationg a non rectangular ROI, with attached labels.
- If a user makes mistake in annotation, the annotation can be reset too.
Note: Every image that is loaded, is resized to 640×480 dimensions, but the output file has points of the bounding boxes as the original image size
The output files generated in the cases have annotation details as,
- First case, every line in the output text file has a image name followed by four points x1 y2 x2 y2, first two representing top left coordinate of the box and the last two representing bottom right coordinates of the box.
- Second case, every line in the output text file has a image name followed by four points x1 y2 x2 y2, first two representing top left coordinate of the box and the last two representing bottom right coordinates of the box. The cropped images are stored in the same folder as the original image, with name, <original_image_name>_cropped.<extension_of_the_original_image>
- Third case, every line in the output text file has a image name followed by a lebel and then the four points x1 y2 x2 y2, first two representing top left coordinate of the box and the last two representing bottom right coordinates of the box. If there are multiple bounding boxes, then after image name there is a label, then four points, followed another label, and the corresponding four points and so on.
- Fourth case, Once the file is saved, the cropped images will be saved in the same forlder as the original image with name as <original_image_name>_cropped_<label>_<unique_serial_id>.<extension_of_the_original_image>.
- Fifth case, The output of the file will be saved as filename, followed by an unique id to the ROI, label of the roi, set of points in the roi, then again another id, its label and the points and so on.
To select any of these cases, select the image/dataset and then press the “Load the image” button.
First case usage
- Select the image or the dataset folder.
- Press the “Load the image” button.
- To create any roi, first left click on top left point of the supposed roi and then right click on the bottom right point of the supposed roi. A green rectangular box will appear.
- Now, if its not the one you meant it, please click “Reset Markings” Button and repoint the new roi.
- If the ROI is fine, press “Select the ROI” button.
- Now, load another image or save the file.
Second case usage
- Select the image or the dataset folder.
- Press the “Load the image” button.
- To create any roi, first left click on top left point of the supposed roi and then right click on the bottom right point of the supposed roi. A green rectangular box will appear.
- Now, if its not the one you meant it, please click “Reset Markings” Button and repoint the new roi.
- If the ROI is fine, press “Select the ROI” button.
- Now, load another image or save the file.
Third case usage
- Select the image or the dataset folder.
- Press the “Load the image” button.
- To create any roi, first left click on top left point of the supposed roi and then right click on the bottom right point of the supposed roi. A green rectangular box will appear.
- Now, if its not the one you meant it, please click “Reset Markings” Button and repoint the new roi.
- If the ROI is fine, please type an integer label in the text box and press “Select the ROI” button.
- Now, you may draw another roi, or load another image, save the file.
- Note: In the third case, the one with multiple ROIs per image, if a boundix box is selected for an image and you are trying to make another and press the reset button, the selected roi will not be deleted. Any selected roi cannot be deleted as of now.
Fourth case usage
- Select the image or the dataset folder.
- Press the “Load the image” button.
- To create any roi, first left click on top left point of the supposed roi and then right click on the bottom right point of the supposed roi. A green rectangular box will appear.
- Now, if its not the one you meant it, please click “Reset Markings” Button and repoint the new roi.
- If the ROI is fine, please type an integer label in the text box and press “Select the ROI” button.
- Now, you may draw another roi, or load another image, save the file.
- Once the file is saved, the cropped images will be saved in the same forlder as the original image with name as <original_image_name>_cropped_<label>_<unique_serial_id>.<extension_of_the_original_image>
Fifth case usage
- Select the image or the dataset folder.
- Press the “Load the image” button.
- To create any roi, Click on the points needed only with left click.
- Now, if its not the one you meant it, please click “Reset Markings” Button and repoint the new roi.
- If the ROI is fine, please type an integer label in the text box and press “Select the ROI” button. A gree color marking covering the region and passing through the points you have selected will appear.
- Now, you may draw another roi, or load another image, save the file.
Thus, this tool, is an extremely important addition to the project and was added as a set of 1600 lines of code on around 6-8 files in the opendetection library.
The corresponding source-codes, brief tutorials and commits, can be accessed here
For Compilation of the library, refer to the link here
Upcoming Work:
a) Resolve the issue of cpp version of AAM and segnet based classifier
b) Heat map generator using cnn ( will require time as its is quite research intensive part)
c) Work to be integrated with Giacomo’s work and to be pushed to master.
d) API Documentation for the codes added.
e) Adding video Tutorials to the blog.
Happy Coding 🙂 !!!